
- Published on
Unlocking the Power of Local LLM Deployment Running AI Models On-Premise
- Authors

- Name
- Adil ABBADI
Introduction
The rapid adoption of Artificial Intelligence (AI) and Machine Learning (ML) in various industries has led to an increased demand for deploying Large Language Models (LLMs) on-premise. Running AI models locally offers numerous benefits, including enhanced security, flexibility, and performance. However, it also presents unique challenges that need to be addressed. In this article, we'll delve into the world of local LLM deployment, exploring its advantages, challenges, and best practices for successful implementation.
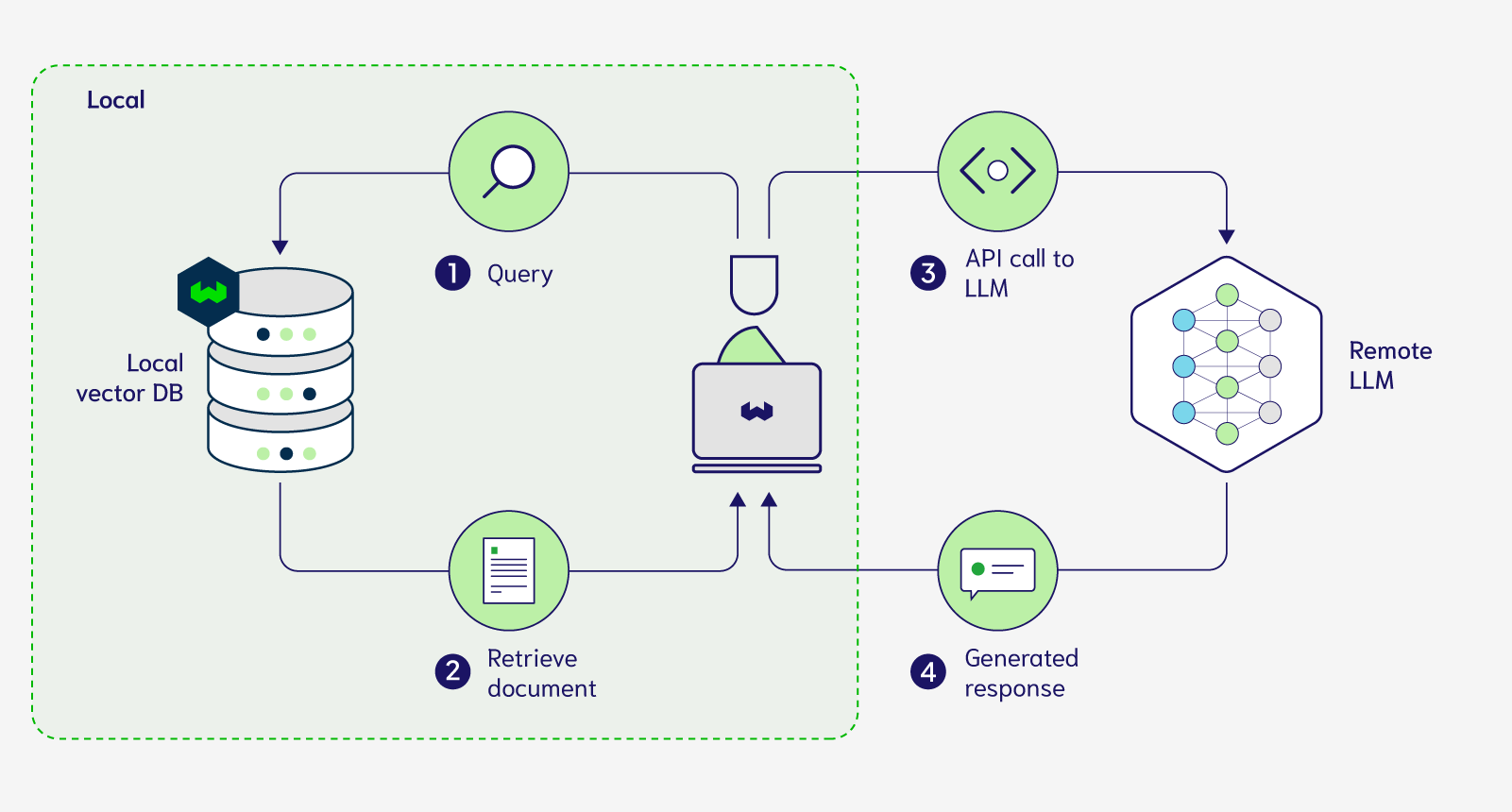
- Benefits of Local LLM Deployment
- Challenges of Local LLM Deployment
- Best Practices for Local LLM Deployment
- Conclusion
- Get Started with Local LLM Deployment Today!
Benefits of Local LLM Deployment
Deploying LLMs on-premise offers several advantages over cloud-based deployment. Some of the key benefits include:
Enhanced Security
By running AI models locally, organizations can better protect sensitive data and maintain control over their model's inference process. This is particularly crucial in industries such as healthcare, finance, and government, where data privacy is paramount.
Flexibility and Customization
Local deployment allows for greater flexibility and customization of AI models. Organizations can fine-tune their models to suit specific use cases, integrate with existing infrastructure, and adapt to changing business requirements.
Improved Performance
Running AI models locally can significantly reduce latency and improve performance. By eliminating the need for cloud-based inference, organizations can reduce the time it takes to process requests and receive responses.
Cost-Effective
Local LLM deployment can be more cost-effective in the long run. By reducing reliance on cloud-based services, organizations can save on infrastructure and operational costs.
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# Load pre-trained model and tokenizer
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# Prepare input data
input_text = "This is an example sentence."
input_ids = torch.tensor([tokenizer.encode(input_text, add_special_tokens=True)])
attention_mask = torch.tensor([tokenizer.encode(input_text, add_special_tokens=True, truncation=True)])
# Perform inference
output = model(input_ids, attention_mask=attention_mask)
Challenges of Local LLM Deployment
While local LLM deployment offers numerous benefits, it also presents several challenges. Some of the key challenges include:
Computational Resources
Running AI models locally requires significant computational resources, including powerful GPUs, CPUs, and memory. Organizations need to ensure they have the necessary infrastructure in place to support local deployment.
Model Management
Managing and maintaining LLMs can be complex and time-consuming. Organizations need to ensure they have the necessary expertise and tools to manage model updates, versioning, and inference.
Data Management
Local LLM deployment requires organizations to manage and store large datasets on-premise. This can be a challenge, particularly for organizations with limited storage capacity or inadequate data management systems.
# Install required packages
pip install transformers torch
# Clone the Hugging Face Transformers repository
git clone https://github.com/huggingface/transformers.git
# Navigate to the cloned repository
cd transformers
# Build the Docker image
docker build -t my-llm-deployment .
Best Practices for Local LLM Deployment
To ensure successful local LLM deployment, organizations should follow best practices, including:
Infrastructure Planning
Conduct thorough infrastructure planning to ensure sufficient computational resources are available to support local deployment.
Model Selection and Optimization
Select the right LLM for the specific use case and optimize the model for local deployment.
Data Management and Security
Implement robust data management and security practices to protect sensitive data and maintain control over model inference.
Continuous Monitoring and Maintenance
Regularly monitor and maintain LLMs to ensure optimal performance, security, and adaptability to changing business requirements.
Conclusion
Local LLM deployment offers numerous benefits, including enhanced security, flexibility, and performance. However, it also presents unique challenges that need to be addressed. By following best practices and understanding the benefits and challenges of local deployment, organizations can unlock the full potential of AI models and drive business success.
Get Started with Local LLM Deployment Today!
Start exploring the world of local LLM deployment and discover how you can harness the power of AI models on-premise.