
- Published on
Unlocking Efficient Inference A Deep Dive into Model Quantization Techniques
- Authors

- Name
- Adil ABBADI
Introduction
As deep learning models continue to grow in complexity and size, the need for efficient inference has become a critical concern. Model quantization techniques have emerged as a powerful solution to optimize model performance while reducing computational resources and latency. In this article, we'll delve into the world of model quantization, exploring the different techniques, benefits, and challenges associated with this powerful optimization method.
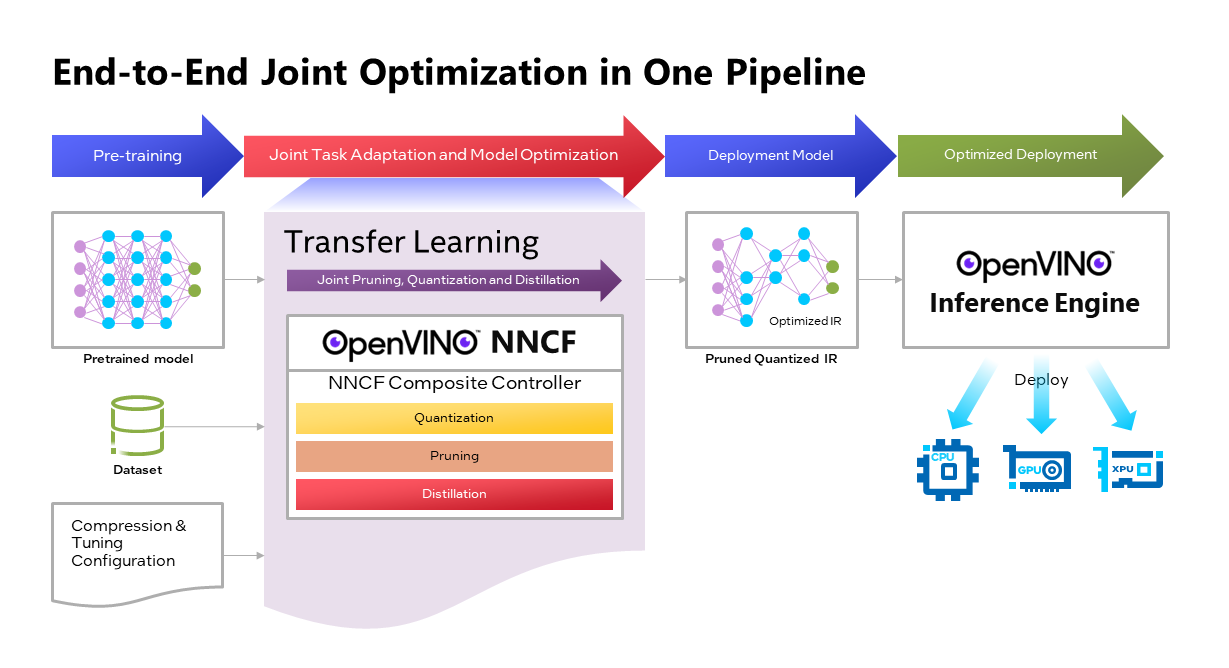
- What is Model Quantization?
- Quantization Techniques
- Challenges and Limitations
- Conclusion
- Final Call-to-Action
What is Model Quantization?
Model quantization is the process of reducing the precision of a model's weights and activations from floating-point numbers to integers. This reduction in precision leads to significant memory savings and faster computation, making models more suitable for deployment on edge devices, mobile devices, and other resource-constrained environments.
Benefits of Model Quantization
The benefits of model quantization are multifaceted:
- Reduced Memory Footprint: Quantized models require less memory storage, making them ideal for devices with limited memory.
- Faster Computation: Integer arithmetic is faster than floating-point arithmetic, leading to faster inference times.
- Energy Efficiency: Quantized models consume less power, making them suitable for battery-powered devices.
- Improved Deployment: Quantization enables the deployment of larger models on resource-constrained devices.
Quantization Techniques
There are several quantization techniques, each with its strengths and weaknesses. Let's explore some of the most popular techniques:
1. Uniform Quantization
Uniform quantization is the simplest form of quantization, where all weights and activations are quantized using a fixed scaling factor. This technique is easy to implement but can lead to accuracy degradation.
import numpy as np
def uniform_quantization(weights, num_bits):
scale = np.max(np.abs(weights)) / (2 ** (num_bits - 1) - 1)
quantized_weights = np.round(weights / scale)
return quantized_weights, scale
2. Non-Uniform Quantization
Non-uniform quantization uses a variable scaling factor for different weight ranges, allowing for more precise quantization.
import numpy as np
def non_uniform_quantization(weights, num_bits):
hist, bins = np.histogram(weights, bins=2 ** num_bits)
thresholds = [(bins[i] + bins[i + 1]) / 2 for i in range(2 ** num_bits - 1)]
quantized_weights = np.digitize(weights, thresholds) - 1
return quantized_weights, thresholds
3. Vector Quantization
Vector quantization groups weights into clusters and represents each cluster using a single vector, reducing the number of unique weights.
import numpy as np
from sklearn.cluster import KMeans
def vector_quantization(weights, num_clusters):
kmeans = KMeans(n_clusters=num_clusters)
kmeans.fit(weights.reshape(-1, 1))
centroids = kmeans.cluster_centers_
quantized_weights = kmeans.predict(weights.reshape(-1, 1))
return quantized_weights, centroids
4. Knowledge Distillation
Knowledge distillation involves training a smaller, quantized model (the student) to mimic the behavior of a larger, pre-trained model (the teacher).
import torch
import torch.nn as nn
class Distiller(nn.Module):
def __init__(self, teacher, student):
super(Distiller, self).__init__()
self.teacher = teacher
self.student = student
def forward(self, x):
teacher_output = self.teacher(x)
student_output = self.student(x)
return teacher_output, student_output
Challenges and Limitations
While model quantization offers significant benefits, it also presents some challenges and limitations:
- Accuracy Degradation: Quantization can lead to accuracy degradation, especially for models with complex architectures or large datasets.
- Over-Quantization: Aggressive quantization can result in over-quantization, leading to accuracy degradation.
- Hardware Support: Not all hardware devices support quantized models, requiring additional software-based implementations.
Conclusion
Model quantization techniques offer a powerful solution for efficient inference, reducing computational resources and latency. By understanding the different quantization techniques, benefits, and challenges, developers can optimize their deep learning models for deployment on resource-constrained devices. As the demand for efficient AI continues to grow, model quantization will play an increasingly important role in powering the next generation of intelligent systems.
Final Call-to-Action
Join the conversation! Share your experiences with model quantization and explore the latest developments in this rapidly evolving field.