
- Published on
Running LLaMA 3 Locally A Guide to Local LLM Deployment
- Authors

- Name
- Adil ABBADI
Introduction
LLaMA 3, a state-of-the-art language model developed by Meta AI, has taken the AI community by storm with its impressive conversational capabilities and versatility. While many users are leveraging LLaMA 3 through cloud-based APIs, running it locally can provide even more flexibility and control over your projects. In this guide, we'll walk you through the process of deploying LLaMA 3 locally, allowing you to harness its full potential for your applications and projects.

- Prerequisites
- Step 1: Install PyTorch and TorchServe
- Step 2: Download the LLaMA 3 Model
- Step 3: Install LLaMA 3
- Step 4: Configure and Run LLaMA 3 Locally
- Step 5: Deploy LLaMA 3 with TorchServe (Optional)
- Conclusion
- Ready to Unlock the Power of LLaMA 3?
Prerequisites
Before diving into the deployment process, ensure you have the following prerequisites in place:
- Python 3.8 or later: LLaMA 3 is built on Python, so you'll need a compatible version installed on your system.
- GPU with at least 16 GB VRAM: LLaMA 3 is a computationally intensive model, and a powerful GPU is required for efficient processing.
- ** PyTorch and TorchServe installed**: You'll need to install PyTorch and TorchServe, the frameworks used by LLaMA 3.
- ** Docker installed (optional)**: If you prefer to use a Docker container for deployment, ensure you have Docker installed on your system.
Step 1: Install PyTorch and TorchServe
To begin, install PyTorch and TorchServe using pip:
pip install torch torchserve
Verify the installation by checking the versions of PyTorch and TorchServe:
python -c "import torch; print(torch.__version__)"
python -c "import torchserve; print(torchserve.__version__)"
Step 2: Download the LLaMA 3 Model
Next, download the LLaMA 3 model weights from the Meta AI repository:
mkdir llama3-models
cd llama3-models
wget https://storage.googleapis.com/meta-llama/llama-3-weights.tar.gz
tar -xvf llama-3-weights.tar.gz
Step 3: Install LLaMA 3
With the model weights downloaded, install LLaMA 3 using pip:
pip install git+https://github.com/meta-ai/llama.git
Step 4: Configure and Run LLaMA 3 Locally
Create a new Python script to load and run LLaMA 3 locally:
import torch
from transformers import LLaMAForConversation, LLaMATokenizer
# Load the model and tokenizer
model = LLaMAForConversation.from_pretrained("llama-3-weights")
tokenizer = LLaMATokenizer.from_pretrained("llama-3-weights")
# Define a function to generate responses
def generate_response(input_text):
inputs = tokenizer.encode_plus(input_text,
add_special_tokens=True,
max_length=512,
return_attention_mask=True,
return_tensors='pt')
output = model(inputs['input_ids'], attention_mask=inputs['attention_mask'])
response = tokenizer.decode(output.logits[0].argmax(-1))
return response
# Test the model
input_text = "Hello, I'm excited to try LLaMA 3 locally!"
response = generate_response(input_text)
print(response)
Run the script to verify that LLaMA 3 is working correctly:
python llama3_local.py
You should see a response generated by the model.
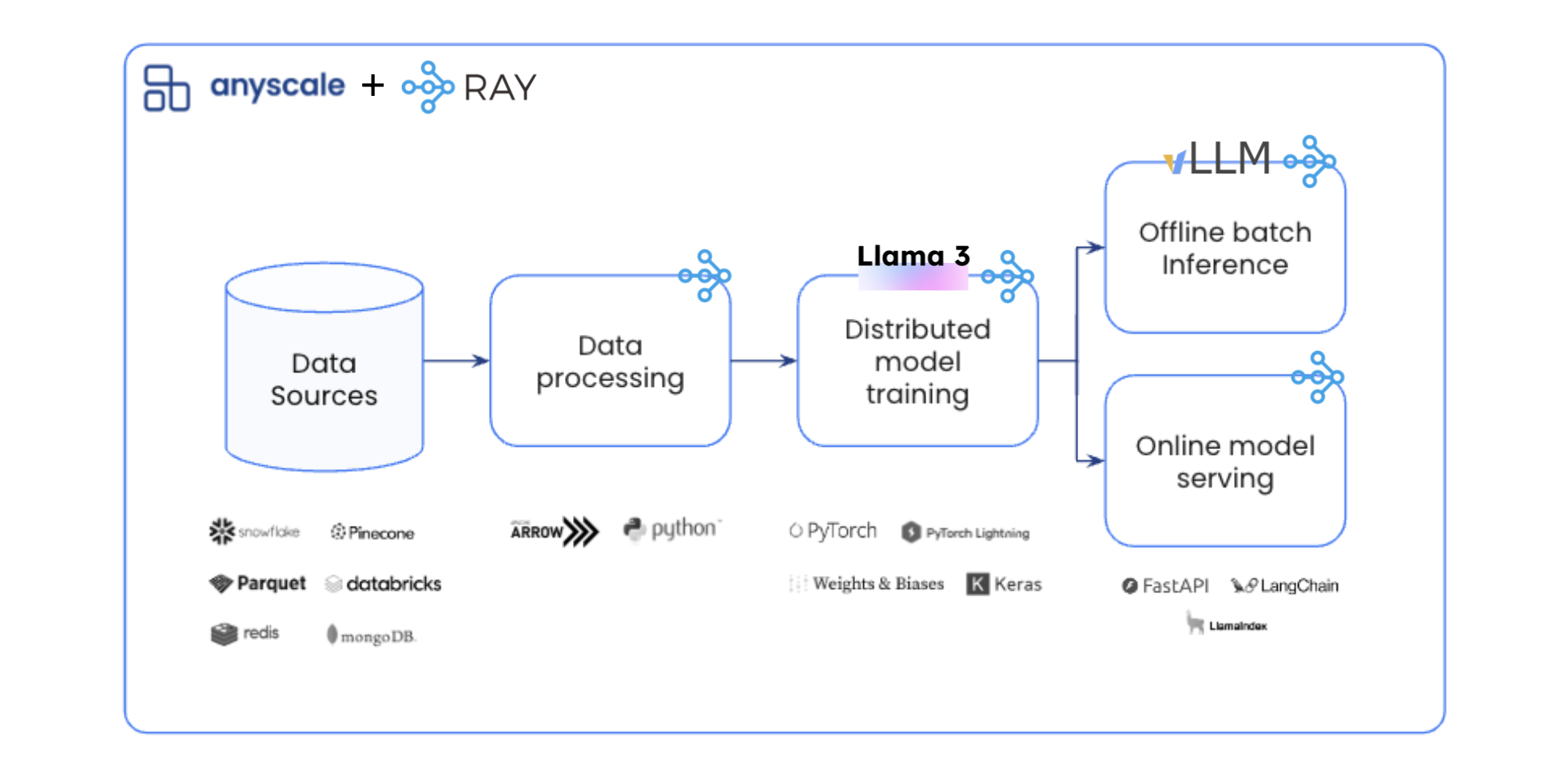
Step 5: Deploy LLaMA 3 with TorchServe (Optional)
For a more production-ready deployment, use TorchServe to manage and serve LLaMA 3:
torchserve --start --model_store llama3-models --model_name llama3-local
This will start the TorchServe server, allowing you to interact with LLaMA 3 using REST API calls.
Conclusion
By following this guide, you've successfully deployed LLaMA 3 locally, unlocking the full potential of this powerful language model for your projects and applications. Whether you're building conversational interfaces, generating text, or exploring the capabilities of LLaMA 3, running it locally provides unparalleled flexibility and control.
Ready to Unlock the Power of LLaMA 3?
Start exploring the possibilities of local LLaMA 3 deployment today and discover new ways to harness the power of this cutting-edge language model.