
- Published on
Mastering Fine-tuning Unlocking BERT s Potential for Specialized NLP Tasks
- Authors

- Name
- Adil ABBADI
Introduction
The advent of transformer-based language models, particularly BERT, has revolutionized the Natural Language Processing (NLP) landscape. BERT's impressive performance on a wide range of tasks has made it a go-to choice for many NLP applications. However, off-the-shelf BERT models may not always be optimal for specialized tasks, where fine-tuning can make all the difference. In this article, we'll delve into the world of fine-tuning BERT models, exploring the benefits, techniques, and best practices for unlocking their full potential.
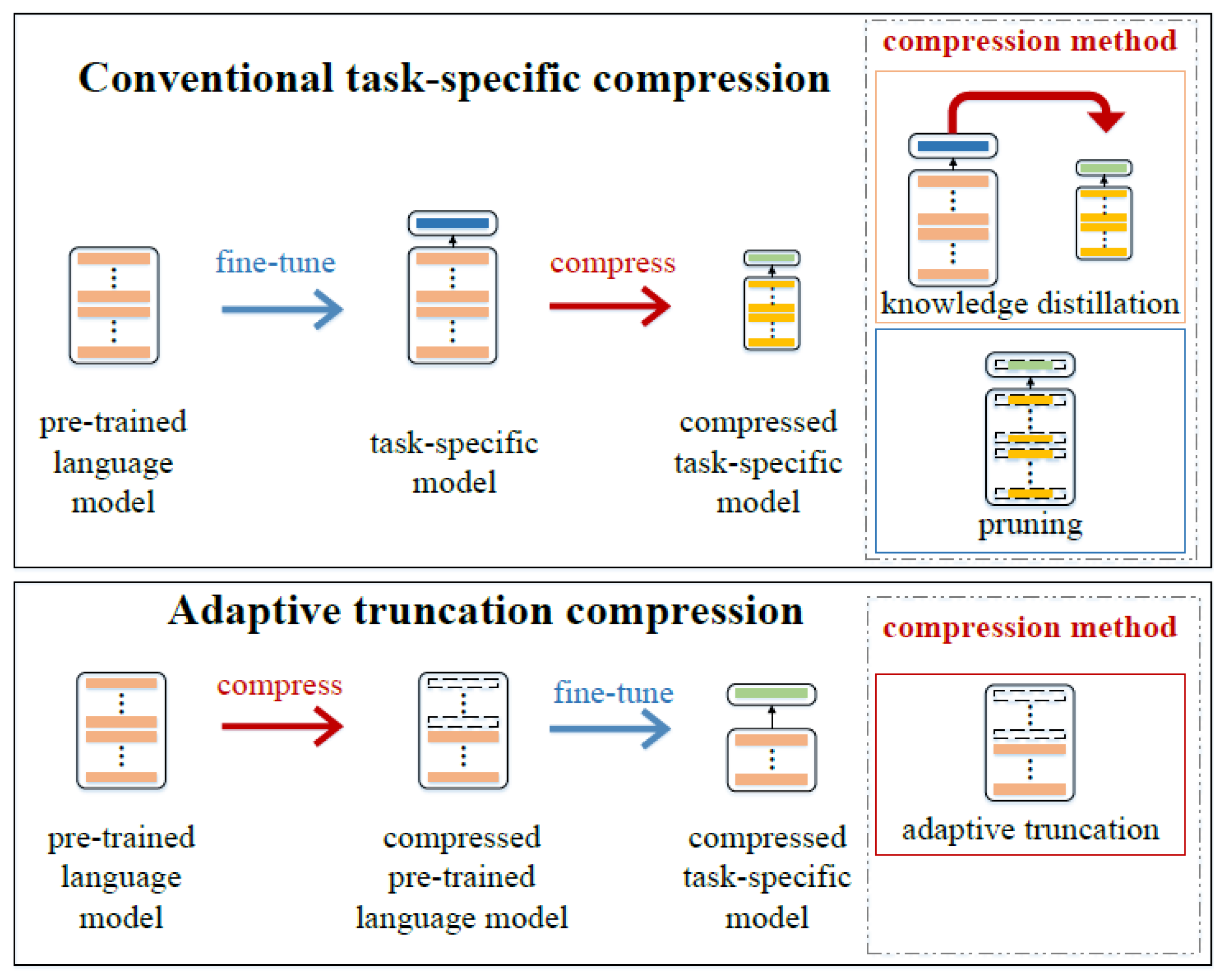
- Understanding BERT and Its Limitations
- Fine-tuning BERT for Specialized Tasks
- Case Studies: Fine-tuning BERT for Specialized NLP Tasks
- Conclusion
- Get Started with Fine-tuning BERT Today!
Understanding BERT and Its Limitations
BERT (Bidirectional Encoder Representations from Transformers) is a powerful language model developed by Google. It's trained on a massive corpus of text data, using a masked language modeling objective to learn contextualized representations of words. These representations can be fine-tuned for specific NLP tasks, such as sentiment analysis, question-answering, and text classification.
While BERT achieves remarkable results in many areas, it's not without its limitations. One major constraint is its generic nature – it's not tailored to specific domains or tasks. This can lead to suboptimal performance when applied to specialized tasks, where domain-specific knowledge and nuances are crucial.
Fine-tuning BERT for Specialized Tasks
Fine-tuning involves adapting a pre-trained BERT model to your specific task, leveraging its learned representations and adjusting them to fit your needs. This process is made possible by the model's ability to learn from a small amount of task-specific data.
Task-Specific Datasets and Data Preparation
The quality and relevance of your dataset play a critical role in fine-tuning BERT. Ensure your dataset is:
- Task-specific: Collect data that closely matches your task's requirements and domain.
- Balanced: Strive for a balanced dataset to avoid biases and ensure the model generalizes well.
- Preprocessed: Perform necessary preprocessing steps, such as tokenization, stemming, and removing stop words.
Fine-tuning Techniques
Several fine-tuning techniques can be employed to adapt BERT to your task:
- Simple Fine-tuning: Update the entire model's parameters using your task-specific dataset.
- Layer-wise Fine-tuning: Freeze certain layers and update only the top layers to adapt to your task.
- ** Adapter-based Fine-tuning**: Introduce additional adapter layers to learn task-specific representations while keeping the pre-trained weights fixed.
import torch
from transformers import BertTokenizer, BertModel
# Load pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Prepare your task-specific dataset and data loader
dataset = ...
data_loader = ...
# Fine-tune the model using your dataset
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for epoch in range(5):
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Hyperparameter Tuning and Model Selection
Hyperparameter tuning is crucial for fine-tuning BERT models. Experiment with different hyperparameters, such as:
- Batch size: Experiment with different batch sizes to find the optimal value for your dataset.
- Learning rate: Adjust the learning rate to control the convergence speed and avoid overshooting.
- Number of epochs: Determine the optimal number of epochs for your task, balancing overfitting and underfitting.
Use techniques like cross-validation and grid search to identify the best combination of hyperparameters. Evaluate your model on a validation set to ensure generalizability.
Case Studies: Fine-tuning BERT for Specialized NLP Tasks
Let's explore some real-world examples of fine-tuning BERT for specialized NLP tasks:
- Medical Text Classification: Fine-tune BERT for classifying medical texts into relevant categories, such as disease diagnosis or treatment options.
- Sentiment Analysis for Financial Texts: Adapt BERT for sentiment analysis in financial texts, capturing nuances specific to the finance domain.
- Question-Answering for Biomedical Literature: Fine-tune BERT for question-answering tasks in biomedical literature, leveraging its ability to understand complex domain-specific language.
Conclusion
Fine-tuning BERT models for specialized NLP tasks can significantly enhance their performance, allowing you to tap into the model's full potential. By following the guidelines and techniques outlined in this article, you'll be well-equipped to adapt BERT to your specific task and domain.
Remember to carefully prepare your dataset, experiment with different fine-tuning techniques, and hyperparameter tuning. With persistence and patience, you'll unlock the true power of BERT and achieve state-of-the-art results in your NLP endeavors.
Get Started with Fine-tuning BERT Today!
Explore the possibilities of fine-tuning BERT models for your specialized NLP tasks. Begin by choosing a task and dataset, and then dive into the world of fine-tuning. Don't hesitate to reach out to the NLP community for guidance and support. Happy fine-tuning!