
- Published on
BERT vs. GPT Understanding Different NLP Architectures
- Authors

- Name
- Adil ABBADI
Introduction
The advent of Artificial Intelligence (AI) has revolutionized the way we interact with machines, and Natural Language Processing (NLP) is at the forefront of this revolution. NLP enables computers to understand, interpret, and generate human language, opening up avenues for applications like chatbots, language translation, and text summarization. Two of the most prominent NLP architectures are BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-training Transformer). In this article, we'll delve into the inner workings of BERT and GPT, highlighting their differences, strengths, and applications.
- The Rise of NLP Architectures
- Comparison of BERT and GPT
- Applications of BERT and GPT
- Conclusion
- Take Your NLP Skills to the Next Level
The Rise of NLP Architectures
NLP has come a long way since its inception in the 1950s. Initially, rule-based approaches dominated the scene, but with the advent of machine learning and deep learning, NLP has become more accurate and efficient. The introduction of transformers in 2017 marked a significant milestone in NLP history. Transformers, unlike traditional recurrent neural networks (RNNs), process input sequences in parallel, making them more efficient and scalable.
BERT: Bidirectional Encoder Representations from Transformers
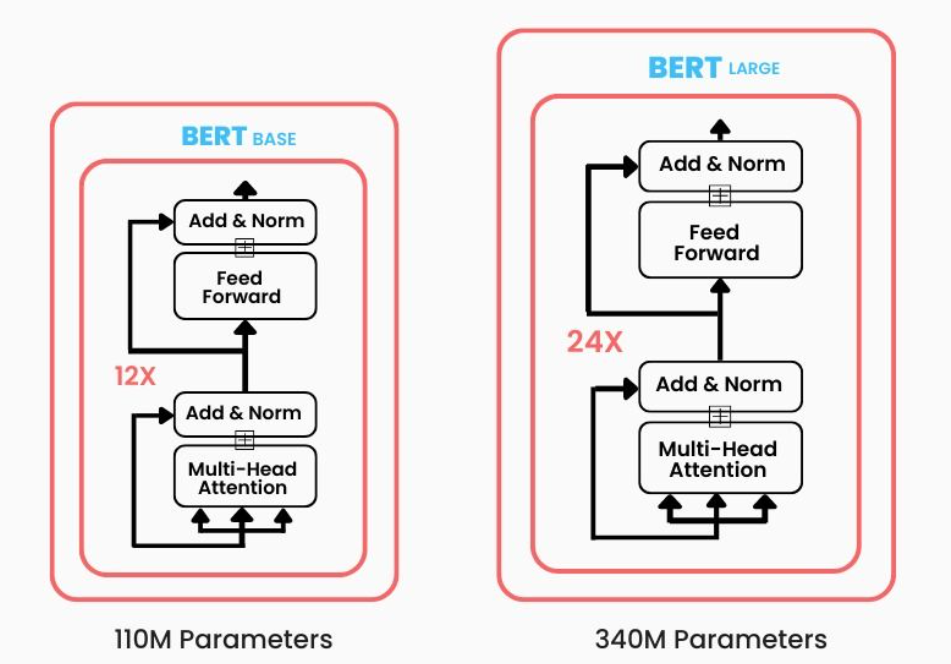
BERT, developed by Google in 2018, is a pre-trained language model that has taken the NLP world by storm. BERT's architecture is based on the transformer encoder, which is a multi-layer bidirectional transformer encoder. This allows BERT to capture context from both the left and right side of a token, making it more effective at understanding natural language.
BERT's training process involves two stages:
- Pre-training: BERT is pre-trained on a large corpus of text (e.g., Wikipedia, BookCorpus) using masked language modeling and next sentence prediction tasks. This step helps BERT learn high-level semantic and syntactic features.
- Fine-tuning: BERT is fine-tuned on a specific downstream task (e.g., sentiment analysis, question-answering) using a small amount of labeled data.
BERT's strengths lie in its ability to:
- Capture contextual relationships between tokens
- Handle out-of-vocabulary (OOV) words
- Perform well on a wide range of NLP tasks
import pandas as pd
import torch
from transformers import BertTokenizer, BertModel
# Load pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Prepare input data
input_text = "This is a sample sentence."
input_ids = torch.tensor([tokenizer.encode(input_text)])
attention_mask = torch.tensor([tokenizer.encode(input_text, return_attention_mask=True)])
# Run input through BERT model
outputs = model(input_ids, attention_mask=attention_mask)
GPT: Generative Pre-training Transformer
GPT, developed by OpenAI in 2018, is a language model that focuses on text generation tasks. GPT's architecture is based on the transformer decoder, which is a multi-layer unidirectional transformer decoder. This allows GPT to generate coherent and context-specific text.
GPT's training process involves a single stage:
- Pre-training: GPT is pre-trained on a large corpus of text (e.g., web articles, books) using a masked language modeling task. This step helps GPT learn high-level semantic and syntactic features.
GPT's strengths lie in its ability to:
- Generate coherent and context-specific text
- Handle long-range dependencies
- Perform well on text generation tasks
import torch
from transformers import GPT2Tokenizer, GPT2Model
# Load pre-trained GPT model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
# Prepare input data
input_text = "This is a sample sentence."
input_ids = torch.tensor([tokenizer.encode(input_text)])
# Run input through GPT model
outputs = model(input_ids)
Comparison of BERT and GPT
While both BERT and GPT are powerful NLP architectures, they differ in their approaches and strengths.
| Architecture | BERT | GPT |
|---|---|---|
| Encoder/Decoder | Encoder | Decoder |
| Training Objective | Masked language modeling + Next sentence prediction | Masked language modeling |
| Contextualization | Bidirectional | Unidirectional |
| Strengths | Capturing contextual relationships, handling OOV words | Generating coherent text, handling long-range dependencies |
Applications of BERT and GPT
Both BERT and GPT have numerous applications in the field of NLP:
- BERT:
- Sentiment analysis
- Question-answering
- Named entity recognition
- Text classification
- GPT:
- Text generation
- Language translation
- Chatbots
- Content generation
Conclusion
BERT and GPT are two pioneering NLP architectures that have pushed the boundaries of natural language understanding and generation. While BERT excels at capturing contextual relationships and handling OOV words, GPT shines at generating coherent text and handling long-range dependencies. By understanding the strengths and differences between these architectures, developers can choose the right tool for their NLP tasks, leading to more accurate and efficient applications.
Take Your NLP Skills to the Next Level
Want to dive deeper into the world of NLP and explore more architectures? Check out our comprehensive guide to NLP architectures and start building your own NLP projects today!